The rapid advancements in Natural Language Processing (NLP) have showcased the versatility and efficacy of Large Language Models (LLMs). These models have demonstrated significant capabilities in compressing vast amounts of information through unsupervised or self-supervised training, enabling impressive few-shot and zero-shot learning performance. These attributes make LLMs particularly attractive for domains where generating extensive task-specific datasets is challenging, such as in biomedical applications. Recent attempts to apply LLMs in biomedical contexts have yielded promising results, highlighting their potential to address complex problems where data scarcity is a significant barrier. Starting from this post, I am planning to write a series on Biomedical LLMs.
1. General Introduction to LLMs
LLMs are deep learning models designed to understand and generate human language. They leverage vast datasets to learn the statistical properties of language, allowing them to generate coherent and contextually appropriate text. The development of LLMs has been significantly influenced by the introduction of the Transformer architecture (Fig. 1) by Vaswani et al. (2017), which enabled models to efficiently (relatively speaking) capture long-range dependencies in text through self-attention mechanisms. Subsequent models such as BERT (Bidirectional Encoder Representations from Transformers) by Devlin et al. (2019) and GPT (Generative Pre-trained Transformer) by Radford et al. (2018) have set new benchmarks in NLP, demonstrating state-of-the-art performance across various tasks.
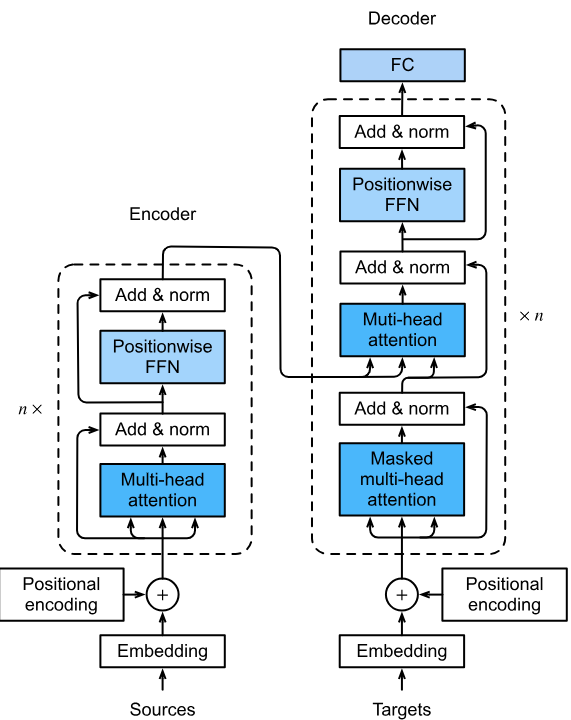
Fig 1. Transformer Architecture.. The nice illustration is from D2l.ai.
2. Training Large Language Models
The training of LLMs involves multiple methodologies designed to enhance their language understanding and generation capabilities. The primary training schemes include:
2.1 Autoregressive Language Modeling (ALM)
Autoregressive language modeling involves training the model to predict the next word in a sequence based on the preceding words:
\begin{equation} \begin{aligned} \pi_\theta (\mathbf{y} \mid \mathbf{x}) = \prod_{t} \pi_\theta (y_t \mid \mathbf{x}, \mathbf{y}_{<t}), \end{aligned} \end{equation}
where $y_t$ is the $t^{\text{th}}$ token in the response and $y_{<t}$ is tokens in the response before $y_t$, $x$ are optional inputs as conditional generation and $\pi_\theta$ is the policy parameterized by $\theta$ for the LLM model.
This approach, utilized by GPT models, enables the generation of text in a sequential manner, ensuring coherence and contextual relevance (Radford et al. 2018). This approach is more and more popular these days. One of the reasons for this trend is not just for the generative capabilities of LLMs, but also because of the belief/hypothesis that the model must be capable understand the language of the world so it can generate coherent and contextually appropriate text. This reminds me of a quote from Richard Feynman on his blackboard at the time of death:
“What I cannot create, I do not understand. " — Richard P. Feynman
Moreover, while ALM typically aim to predict the next word in a sequence, a recent study has explored alternative ALM variants that predict multiple subsequent tokens simultaneously (Gloeckle et al. 2024). This Multi-token Prediction approach has demonstrated improved performance, including faster inference and enhanced reasoning capabilities. For more details on these advancements and solutions to the high memory usage issues associated with multiple token prediction, please refer to Gloeckle et al. 2024.
2.2 Masked Language Modeling (MLM)
Masked language modeling, employed by models such as BERT, involves masking certain words in a sentence and training the model to predict these masked words based on the surrounding context.
\begin{equation} \begin{aligned} p(y_{\text{masked}} \mid y_{\text{unmasked}}) = g \circ f(y_{\text{unmasked}}), \end{aligned} \end{equation}
where $y$ are the tokens, $f$ represents the contextualized embeddings of the unmasked tokens and $g$ is linear probing followed by a softmax operation that returns the probabilities of masked tokens being particular tokens in the context, i.e. $p(y_{\text{masked}} \mid y_{\text{unmasked}})$.
This fill-in-the-blank Cloze task in a bidirectional training fashion allows the model to capture contextualized representation of the inputs, leading to improved performance on a range of NLP tasks (Devlin et al., 2019).
2.3 Other Training Schemes
It’s worth noting that there are additional training tasks in BERT except for the masked language modeling task. BERT also has a pre-training task that involves next sentence prediction (NSP) that is used to train the model to predict whether two segments are adjacent to each other in a document. This task aims to learn the relationships between segments for downstream tasks such as summarization and question answering that require reasoning about the relationships between pairs of sentences. However, there are other studies showing removing the NSP task can match or slightly improve the downstream tasks (Liu, et al. 2019).
Other notable training schemes include sequence-to-sequence learning, as implemented in models like T5 (Text-to-Text Transfer Transformer) (Raffel et al., 2020). This approach involves training the model to convert one sequence of text into another. The multitask settings makes it versatile for tasks such as translation, summarization, and question answering.
Moreover, as I plan to write about later, diffusion models have also been explored in LLMs (Singh, et al. 2023, Wang, et al. 2024). These models iteratively transform a simple noise distribution into a complex data distribution, effectively learning to reverse a diffusion process. This technique, although more common in image generation tasks, is being explored for text generation to enhance the diversity and quality of generated sequences.
3. Typical LLM Frameworks
Modern large language models (LLMs) are built on top of the transformer architecture (Fig. 1), using various architectural frameworks tailored to different purposes. The most prevalent frameworks include:
3.1 Encoder-Only
Encoder-only models, such as BERT, focus on understanding the input text. These models are optimized for tasks like text classification and named entity recognition, where comprehending the input context is crucial (Devlin et al. (2019)). The bidirectional transformer encoder allows the model to capture dependencies in both directions of the sequences, which is excellent for understanding context but problematic for generating text one token at a time. Therefore, encoder-only models are typically used for representation learning in various downstream tasks.
3.2 Decoder-Only
Decoder-only models, such as GPT, are designed for text generation tasks. They excel at producing coherent and contextually relevant text, making them suitable for applications in language modeling, text completion, and creative writing (Radford et al. 2018). The attention is almost always causal (forward directional), meaning the model can see only previous tokens (prefix). With appropriate prompting, decoder-only architectures can also perform downstream tasks like text classification.
3.3 Encoder-Decoder
The encoder-decoder framework, exemplified by models like T5 (Raffel et al., 2020) and BART (Bidirectional and Auto-Regressive Transformers) (Lewis et al., 2020), involves an encoder to process the input text and a decoder to generate the output text. This architecture is particularly effective for tasks that require text transformation, such as translation and summarization.
However, encoder-decoder models may struggle with autoregressive generation. This is due to the bidirectional nature of encoders requiring full context bidirectionally and the need for the encoder to reprocess the entire sequence, including newly generated tokens, for each new token generation. This re-encoding step is computationally expensive and time-consuming, making the autoregressive process less efficient. While encoder-decoder models can theoretically use only the decoder for generation, this approach does not fully leverage the encoder’s parameters, leading to suboptimal use of the model’s capacity and parameters. Therefore, decoder-only architectures are more commonly used for tasks requiring generation, such as text generation and question answering.
3.4 Decoder-Decoder
To be more scalable and resource-efficient for long-context language modeling, YOCO (You Only Cache Once), a decoder-decoder architecture, has been recently proposed (Sun et al., 2024). YOCO consists of two main components: the self-decoder and the cross-decoder (Fig. 2). The self-decoder efficiently processes the input sequence to generate a set of global key-value (KV) caches via efficient self-attention mechanisms (such as sliding-window attention or gated retention). These caches are then reused by the cross-decoder, which employs cross-attention to generate the output sequence. This design allows YOCO to reuse the KV caches efficiently, achieving substantial improvements in memory consumption and inference speed without sacrificing performance compared to decoder-only transformers. (Traditional decoder-only models cache the key-value pairs for all tokens generated so far for each layer of the decoder, leading to multiple layers of caches being maintained simultaneously.) By caching the KV pairs only once and reusing them across multiple layers in the cross-decoder, YOCO significantly reduces the GPU memory footprint. This approach avoids the exponential growth of memory requirements typically seen in decoder-only models, where each layer and each token generation step involve separate KV caching.
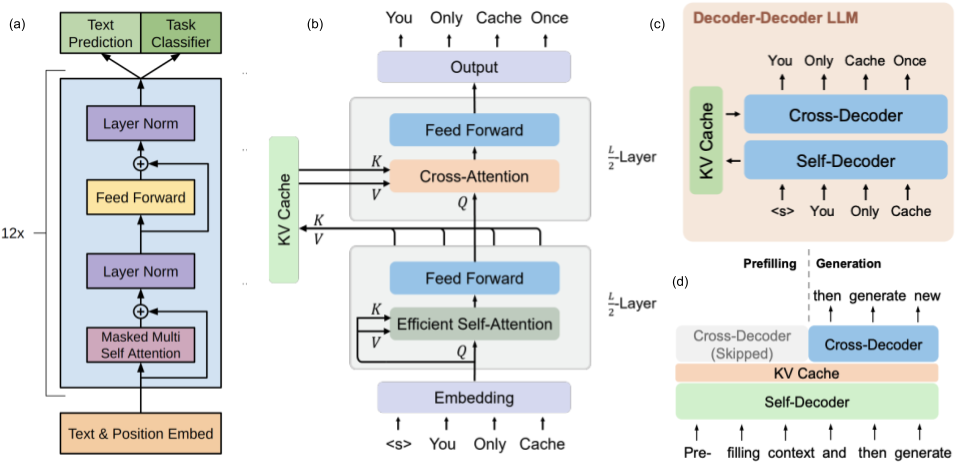
Fig 2. Decoder-only vs Decoder-Decoder. (a) GPT’s decoder-only architecture. (b) & (c) Decoder-decoder architecture. (d) YOCO inference process. (a) is from Radford et al. 2018 and (b-d) are from Sun et al. 2024.
3.5 Other Architectures
Beyond these frameworks, ongoing research continues to explore new architectures and training methodologies to enhance LLM capabilities. Hybrid models and multimodal models, which integrate text with other data types (e.g., images, audio) (Radford et al. 2021), represent cutting-edge advancements in the field.
Another notable innovation is the prefix decoder architecture. This type of hybrid model modifies the masking mechanism of causal decoders (i.e., decoder-only architecture) to enable bidirectional attention over prefix tokens while maintaining unidirectional attention on generated tokens. Consequently, prefix decoders can bidirectionally encode the prefix sequence and autoregressively predict output tokens using shared parameters. For a more detailed illustration of such prefix language models, I recommend Cameron Wolfe’s blog “T5: Text-to-Text Transformers” (link1, link2).
4. Employing Pre-Trained LLMs
Pre-trained LLMs serve as foundation models that can be employed for specific tasks using several techniques, starting with zero-shot approaches and moving towards more customized fine-tuning methods.
4.1 Prompting
Prompting involves crafting specific input prompts to guide the model’s output. This technique leverages the model’s pre-existing knowledge and can be used to elicit specific information or perform particular tasks. Effective prompting can significantly enhance the model’s performance on a wide range of tasks without additional fine-tuning that updates the LLM itself. Prompting is particularly effective with autoregressive language models (ALMs) and models with a decoder architecture, such as GPT.
Consider a pre-trained language model being used in the context of prompting. The input sentence is:
"Tell me a story about poison apple."
With prompting, the model uses this input to generate a continuation based on its pre-trained knowledge, producing an output such as:
"Once upon a time, in a faraway kingdom, there lived a beautiful princess who..."
Here, the model utilizes its extensive training data to create coherent and contextually appropriate text without additional fine-tuning.
4.2 In-Context Learning
In-context learning allows the model to learn tasks by providing examples within the input context, without additional training. This method leverages the model’s ability to infer patterns and relationships from the provided examples, enabling it to perform new tasks based on the contextual information alone. This approach works well with models that have a decoder component.
Consider a pre-trained language model using in-context learning. The model is given the following context:
"Q: What is the capital of France? A: Paris. Q: What is the capital of Germany?"
With in-context learning, the model uses this context to infer the pattern and generate the appropriate continuation:
"A: Berlin."
Here, the model leverages the provided examples to predict the answer to the new question based on the pattern observed in the context.
Additionally, Dai et al. 2022 demonstrate that in-context learning can mimic the effects of explicit fine-tuning in GPT models, essentially serving as a form of implicit fine-tuning (Fig. 3). They illustrate that GPT generates meta-gradients for in-context learning during forward computation. In-context learning then utilizes these meta-gradients, applying them to the model via attention mechanisms. This meta-optimization in ICL is analogous to the explicit fine-tuning process, where model parameters are directly updated through back-propagated gradients.
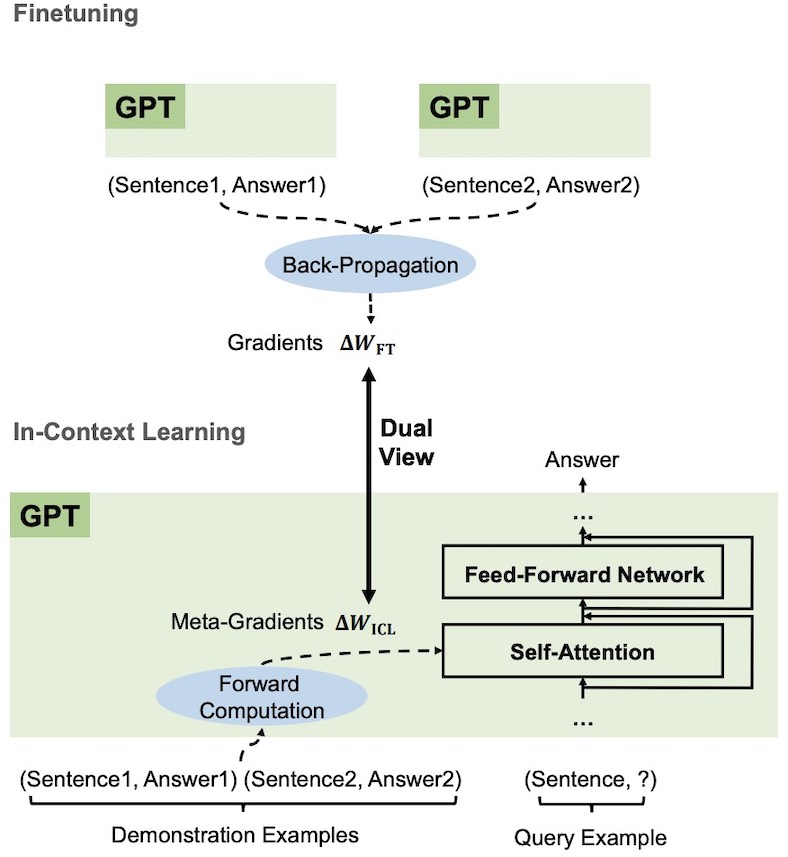
Fig 3. Comparison of Finetuning and In-Context Learning (ICL) in GPT Models. The upper section illustrates the traditional fine-tuning process where the GPT model is updated with gradients ($ΔW_{FT}$) via back-propagation using pairs of sentences and their corresponding answers. The lower section demonstrates the in-context learning process, where demonstration examples (pairs of sentences and answers) are used to produce meta-gradients ($ΔW_{ICL}$)through forward computation. These meta-gradients are then applied to the model using self-attention and feed-forward network mechanisms to generate answers for query examples. The figure highlights the dual view of meta-optimization in ICL and explicit fine-tuning. The chart is the Fig. 1 from Dai et al. 2022.
4.3 Instruction Learning
Instruction learning/tuning involves providing the model with explicit instructions within the input text to perform a specific task. This method allows the model to understand and execute complex tasks by interpreting the given instructions. Instruction learning is particularly useful for tasks requiring precise control over the model’s behavior and is suitable for models with decoder components. The model is fine-tuned on a dataset with examples showing how to follow explicit instructions. This process trains the LLMs to learn how to do in context learning, granting the models’ capability of zero-shot generalization from multitask training.
Consider a pre-trained language model being adapted through instruction learning. The instruction is:
"Here is a Chinese sentence that is often used to say Hi. Translate it to English: '你吃了吗?'"
With instruction learning, the model uses this directive to perform a specific task, generating the output:
"Hello, how are you?"
In this case, the model is fine-tuned on a dataset of translation pairs to follow explicit instructions for translating text between languages.
4.4 Chain of Thought (CoT)
Extended from in-context learning, CoT prompting enhances the model’s reasoning capabilities by guiding it through a step-by-step problem-solving process. This technique can be applied in few-shot or zero-shot scenarios and includes methods like “let’s think step by step” and self-consistency.
4.4.1 Few-Shot CoT Prompting
Few-shot CoT prompting involves providing the model with several examples of the reasoning process needed to solve a task. By showing the model how to work through a problem step-by-step, it learns to apply a similar approach to new problems.
Consider a pre-trained language model being used with few-shot CoT prompting. The input is:
"Example 1:
Q: If you have 5 apples and you give 2 away, how many do you have left? A: You start with 5 apples. You give away 2 apples. So, you have 3 apple left.
Example 2:
Q: If you have 6 books and you buy 3 more, how many do you have in total? A: You start with 6 books. You buy 3 more books. So, you have 9 books in total."
New Problem: Q: If you have 10 candies and you eat 8, how many do you have left?"
Using few-shot CoT prompting, the model generates:
"You start with 10 candies. You eat 8 candies. So, you have 2 candies left."
4.4.2 Zero-Shot CoT Prompting
Zero-shot CoT prompting involves instructing the model to think through the problem step-by-step without providing examples. This approach relies on the model’s ability to generalize from its training data.
Consider a pre-trained language model being used with zero-shot CoT prompting. The input is:
"Q: If you have 9 oranges and you give 3 to your friend, how many do you have left? **Let's think step by step.**"
Using zero-shot CoT prompting, the model generates:
"Let's think step by step. You start with 9 oranges. You give 3 oranges to your friend. So, you have 6 oranges left."
4.4.3 Self-Consistency
Self-consistency is a technique used to improve the reliability of CoT prompting. It involves generating multiple reasoning paths and then selecting the most consistent answer among them. This method helps mitigate the variability in the model’s outputs.
Consider a pre-trained language model using self-consistency in CoT prompting. The input is:
"Q: If you have 12 balloons and you give 6 to your friend, how many do you have left? Let's think step by step."
The model generates multiple reasoning paths:
"Path 1: You start with 12 balloons. You give 6 balloons to your friend. So, you have 7 balloons left."
"Path 2: You start with 12 balloons. You give 6 balloons to your friend. So, you have 6 balloons left."
"Path 2: You start with 12 balloons. You give 6 balloons to your friend. So, you have 6 balloons left."
The final answer is determined by the consistency across paths:
"6 balloons."
4.4.4 Least-to-Most Prompting
Least-to-most prompting is a teaching strategy that helps students learn new skills by using a sequence of prompts that start with the least intrusive and progress to the most intrusive. It breaks down a complex task into simpler sub-tasks and solves each one step-by-step. This method helps the model handle more complex problems by simplifying the process.
Consider a pre-trained language model using least-to-most prompting. The input is:
"Q: Solve the equation 2x + 3 = 11 step-by-step."
The model breaks down the problem:
"Step 1: Subtract 3 from both sides. 2x = 8.
Step 2: Divide both sides by 2. x = 4."
The final answer is:
"x = 4."
To learn more prompting engineering, check out the Learn Prompting website. Of course, except for hard prompting, there are other ongoing research and applications that aim to generate optimal prompts or soft prompts (a numerical vector like the adapter, see more in prefix-tuning) via another LLM model.
4.5 Retrieval-Augmented Generation (RAG)
RAG combines retrieval-based methods with generation capabilities to improve the accuracy and relevance of the model’s outputs. In RAG, the model first retrieves relevant documents or information from a large corpus and then generates a response based on this retrieved information. This approach enhances the model’s performance on tasks requiring up-to-date or domain-specific knowledge.
4.6 Vocabulary Extension
Vocabulary extension involves adding new tokens to the model’s existing vocabulary to better handle domain-specific terminology. This is crucial in fields like biomedicine, where specialized terms frequently appear that were not part of the original corpus (i.e., out-of-vocabulary). The process typically involves:
- Updating the Tokenizer: Include new tokens by training a new tokenizer on the domain-specific corpus and merging its vocabulary with the existing one.
- Modifying the Embedding Layer: Resize the embedding matrix to accommodate the new tokens and initialize their embeddings, either randomly or using informed methods.
- Fine-tuning the Model: Adjust the new embeddings and model parameters by fine-tuning the model on the new domain corpus.
- Evaluating the Model: Ensure the model effectively handles the new tokens by evaluating it on a validation set from the new domain and making necessary adjustments.
This process enables the LLM to understand and generate text in specialized domains effectively.
Apart from extending the vocabulary and fine-tuning a pre-trained LLM, other strategies like feature fusion can handle unknown tokens in specific domains. Feature fusion involves adding additional features to the embeddings of known tokens. This can include using pre-trained embeddings from various sources or incorporating domain-specific information. For example, when working with LLMs trained on DNA sequences, methylation status may be available in the target domain corpus but not in the original training corpus. By combining these different types of features, the model’s performance is enhanced, especially in handling domain-specific terminology.
4.7 Supervised Fine-Tuning
Supervised fine-tuning (SFT) involves continuing the training of a pre-trained model using domain-specific or task-specific data. SFT is a specific type of fine-tuning where the task-specific dataset used for fine-tuning includes labeled data. This labeled data is used to provide explicit guidance to the model on how to adjust its parameters. This process adjusts the model parameters to better suit the nuances of the new domain or new task. For example, a pre-trained LLM might be fine-tuned on a dataset of clinical notes to improve its ability to understand and generate medical text, significantly enhancing its performance on specialized tasks. SFT can be employed for both GPT-style and BERT-style LLMs.
4.8 Alignment via RFHF
Alignment through reinforcement learning from human feedback (RFHF) aims to fine-tune the unsupervised LMs to align the model’s outputs with human values and preferences, ensuring that the generated responses are accurate, ethical, and contextually appropriate (Ziegler, et al. 2019, Ouyang, et al. 2022). In this approach, human feedback is used to reward or penalize the model’s predictions, guiding it to produce more desirable and reliable outputs. This method is particularly useful for ensuring that LLMs generate responses that are not only accurate but also ethically and contextually appropriate.
To obtain human feedback, additional data called comparison data that show different human rankings on different model outputs given the same input. Such a comparison data will be used to build a reward model as human evaluators. Human evaluators review the model’s outputs and provide feedback, which is used to adjust the model’s parameters as fine-tuning via minimize the following loss:
\begin{equation} \begin{aligned} \mathcal{L_r(\pi_t)} = -\mathbb{E}_{x \sim p_d, y \sim \pi_t} \left[ r(x, y) - \beta \log \frac{\pi_t(y \mid x)}{\pi_r(y \mid x)} \right], \end{aligned} \end{equation}
where $r$ is the reward function reflecting human preferences in the comparison data $p_d$. $\pi_r$ is the original reference model used for regularizing $\pi_t$ with Kullback–Leibler divergence. $\beta$ is the hyperparameter for controlling the regularization strength. The objective here is to get large reward without deviating from the original reference LLM too much.
To optimize eq 3 for human preference alignment, there are several approaches broadly categorized into reward-based methods like Proximal Policy Optimization (PPO) (Ouyang, et al. 2022) and reward-free methods like Direct Preference Optimization (DPO) (Rafailov, et al. 2024) and Self-Play Preference Optimization (SPPO) (Wu, et al. 2024).
4.8.1 PPO
After a reward model $r_\phi$ is constructed using the human-labeled comparison data, eq 3 can be explicitly optimized with online RL algorithms. PPO is a policy gradient method in RL algorithm designed to stabilize training by using a clipped objective function (Schulman, et al. 2017). Compared to other RL algorithms, the key idea for PPO is to update the policy in small steps to prevent large deviations from the previous policy, which can lead to instability.
4.8.2 DPO
Direct Preference Optimization (DPO) simplifies RFHF by directly optimizing preference probabilities without training a separate reward model (Rafailov, et al. 2024). It leverages the log-likelihood ratio of preferred responses to non-preferred ones. The DPO loss function is:
\begin{equation} \begin{aligned} \mathcal{L_{\text{DPO}}}(\pi_t; \pi_r) = -\mathbb{E}_{(x,y_w,y_l) \sim \mathcal{D}} \left[ \log \sigma \left( \beta \log \left( \frac{\pi_t(y_w | x)}{\pi_r(y_w | x)} \right) - \beta \log \left( \frac{\pi_t(y_l | x)}{\pi_r(y_l | x)} \right) \right) \right], \end{aligned} \end{equation}
where $y_w$ and $y_l$ are the preferred and less preferred responses given the input $x$, respectively, $\sigma$ is the sigmoid function and $\beta$ is a scaling parameter. This method directly targets the improvement of preference probabilities, which can lead to more stable and efficient training compared to methods requiring a reward model.
DPO avoids the complexity and potential biases introduced by training a separate reward model. It aligns the language model with human preferences through a straightforward optimization process. However, DPO might struggle with data sparsity and non-transitive preferences, which can limit its effectiveness in some scenarios.
4.8.3 SPPO
Self-Play Preference Optimization (SPPO) formulates the alignment problem as a two-player constant-sum game, aiming to find the Nash equilibrium policy that consistently aligns with human preferences (Wu, et al. 2024). SPPO uses a self-play mechanism to iteratively refine the model by generating responses and evaluating them using a pre-trained preference model. The policy update is given by:
\begin{equation} \begin{aligned} \pi_{t+1}(y | x) \propto \pi_t(y | x) \exp \left( \eta P(y \succ \pi_t | x) \right), \end{aligned} \end{equation}
where $P(y \succ \pi_t | x) = \mathbb{E}_{y’ \sim \pi_t(\cdot | x)}[P(y \succ y’ | x)]$ is the winning probability.
The SPPO loss function ensures that the policy iteratively improves by fitting the log-probabilities of the model’s responses to the empirical winning probabilities. This approach effectively handles intransitive and irrational human preferences by directly working with preference probabilities, which cannot be trivially achieved by symmetric pairwise loss functions like DPO. SPPO was shown significant improvements in alignment tasks, outperforming iterative DPO and other methods (e.g. Identity Preference Optimization IPO) in various benchmarks without the need for external supervision.
4.9 Efficient Fine-Tuning
As the size of foundational LLMs (Large Language Models) today is typically quite large, fine-tuning these models can be computationally challenging. Efficient fine-tuning techniques aim to reduce the computational resources required for fine-tuning large models. This enables large language models to be adapted to specific tasks with significantly reduced computational costs, making them more accessible and practical for a broader range of applications.
A few common Parameter-Efficient Fine-Tuning (PEFT) methods are briefly described below.
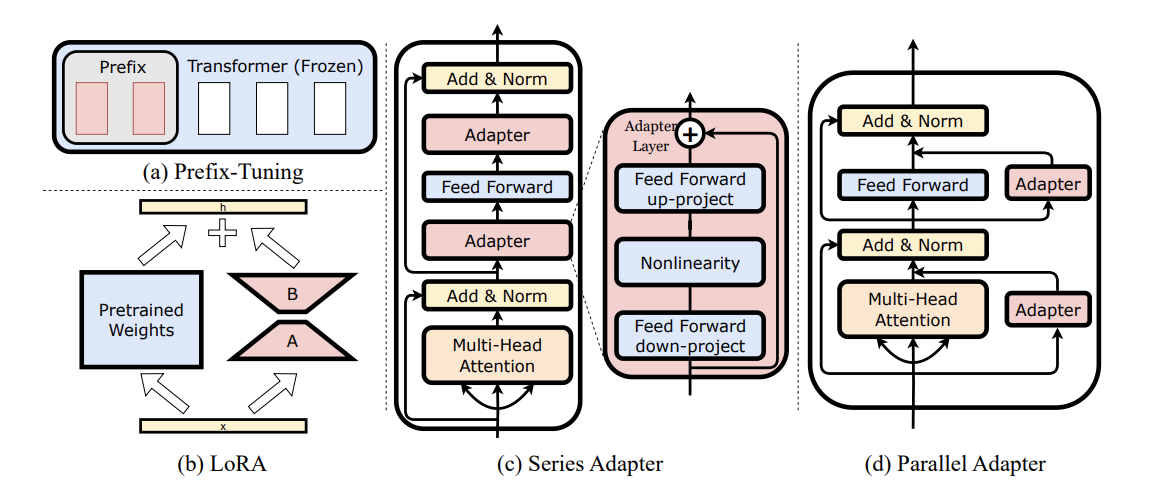
Fig 4. Model architectures for different adaptation. (a) Prefix-Tuning, (b) LoRA,(c) Series Adapter, and (d) Parallel Adapter. The chart is the Fig. 1 from Hu, et al. 2023. Using this fig here for illustration purpose.
4.9.1 Low-Rank Adaptation (LoRA)
Low-Rank Adaptation (LoRA) reduces the number of trainable parameters by learning low-rank updates to the pre-trained weights. This method adapts only a small subset of the model’s parameters, allowing for quick and resource-efficient updates. LoRA is particularly useful in scenarios with limited computational resources.
The key idea behind LoRA is to approximate the weight update matrix $\Delta W$ using two lower-rank matrices $A$ and $B$:
\begin{equation} \begin{align*} W = W + \Delta W \\\ \Delta W = A \times B, \end{align*} \end{equation}
where $A \in \mathbb{R}^{d \times r}$ and $B \in \mathbb{R}^{r \times k}$, with $r$ being much smaller than the original dimensions $d$ and $k$. This approximation reduces the number of parameters from $d \times k$ to $d \times r + r \times k$.

Fig 5. LoRA. Imagine a visual representation showing the original large matrix $W$ and its low-rank approximation through matrices $A$ and $B$. The GIF is from HuggingFace. I recommend checking the link for more information about hte adapters.
4.9.2 Adapter Modules
Adapter modules involve adding small, trainable layers between the layers of a pre-trained model 1. These adapters can be fine-tuned for specific tasks without altering the original model parameters. This approach significantly reduces the amount of training data and computational power required compared to full fine-tuning.
Mathematically, if $h$ is the hidden state of a layer, an adapter module can be represented as:
\begin{equation} \begin{aligned} h’ = h + f_{\text{adapter}}(h), \end{aligned} \end{equation}
where $f_{\text{adapter}}$ is a lightweight feed-forward network with a bottleneck architecture, typically much smaller than the original layer. Please read Fig 4 (c & d) for checking series abd parallel adapters, two common ways to place the adapters:
4.9.3 Soft Prompting and Prefix-Tuning
Unlike providing exact instruction as hard prompts, soft prompting involves adding a series of trainable tokens (soft prompts) to the input of a pre-trained model. These soft prompts compose a small continuous vector, that is prepended to the input sequence (Fig 4(a)). This soft prompt vector is fine-tuned while the rest of the model’s parameters remain fixed. This method is especially useful when adapting the model for tasks like classification, generation, or answering questions, without needing extensive retraining or fine-tuning of the model itself.
Given an input sequence $x = [x_1, x_2, \ldots, x_n]$, soft prompting modifies it to:
$x’ = [p_1, p_2, \ldots, p_m, x_1, x_2, \ldots, x_n]$, where $[p_1, p_2, \ldots, p_m]$ are the learned prefix vectors.
Consider a pre-trained language model being adapted to a specific task, such as sentiment analysis. The original input sentence is:
"I had a great day at the park."
With soft-prompting, a learned soft prompt is prepended to this input:
$[p_1, p_2, p_3, p_4, p_5]$ + "I had a great day at the park."
Here, $[p_1, p_2, p_3, p_4, p_5]$ are the soft prompting vectors. During fine-tuning, only these soft prompting vectors are updated while the rest of the model's parameters remain fixed. This allows the model to adapt to the sentiment analysis task using minimal additional computation.
Prefix-tuning extends the idea of soft prompts by not only prepending trainable vectors to the input sequence but also integrating these vectors into intermediate stages of the model. This technique involves learning a series of continuous vectors, or “prefixes,” that are inserted not just at the input but potentially at multiple points within the transformer layers (see the Illustration of prefix tuning in Sebastian Raschka’s blog). This operation effectively modifies both the input and the intermediate representations throughout the model. Compared to soft prompting, prefix-tuning likely offers enhanced control over the model’s behavior, potentially leading to improved performance on complex tasks.
4.9.4 Other Parameter-Efficient Fine-Tuning Techniques
Other PEFT techniques focus on modifying only a subset of the model’s parameters or applying quantization techniques to reduce computational overhead. These methods maintain model performance while minimizing the resources needed for fine-tuning. Some examples are:
-
BitFit (Zaken, et al. 2021): Only the bias terms of the model are fine-tuned. Mathematically, for a weight matrix $W$ and bias $b$, only $b$ is updated:
$W’ = W$
$b’ = b + \Delta b$
-
QAT (Quantization Aware Training) (Liu, et al. 2023): Quantization Aware Training applies quantization during training, which reduces the precision of the model parameters, leading to lower computational requirements.
5. Plans for this Series
This introductory post should have provided sufficient fundamentals about large language models (LLMs). Subsequent posts in this series will delve into specific applications of LLMs in the biomedical domain. The planned topics include
- Genomic Language Models: Covering general genomic applications, including DNA/RNA LLMs and gene LLMs.
- Protein Language Models: Exploring the use of LLMs in understanding protein structures and functions.
- Chemistry Language Models: Highlighting the role of LLMs in chemical research, including drug discovery and molecular analysis.
- Other Biomedical LLMs: Discussing models for universal biological sequence LLMs, medical imaging, generalized biological understanding through multimodal data integration, and other emerging applications in the biomedical field.
While this intro post focuses on some general intro to LLMs, I look forward to more exploration of how LLMs are transforming biomedical research and applications in the coming posts of this series.
Citation
If you find this post helpful and are interested in referencing it in your write-up, you can cite it as
Xiao, Jiajie. (May 2023). Biomedical LLMs: Intro. JX’s log. Available at: https://jiajiexiao.github.io/posts/2024-05-10_biollm_intro/.
or add the following to your BibTeX file.
@article{xiao2024_biollm_intro,
title = "Biomedical LLMs (1): Intro",
author = "Xiao, Jiajie",
journal = "JX's log",
year = "2024",
month = "May",
url = "https://jiajiexiao.github.io/posts/2024-05-10_biollm_intro/"
}
References
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
-
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
-
Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training. OpenAI.
-
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., … & Stoyanov, V. (2019). Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
-
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., … & Liu, P. J. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140), 1-67.
-
Mukul Singh, José Cambronero, Sumit Gulwani, Vu Le, Carina Negreanu, and Gust Verbruggen. 2023. CodeFusion: A Pre-trained Diffusion Model for Code Generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 11697–11708, Singapore. Association for Computational Linguistics.
-
Wang, X., Zheng, Z., Ye, F., Xue, D., Huang, S., & Gu, Q. (2024). Diffusion Language Models Are Versatile Protein Learners. arXiv preprint arXiv:2402.18567.
-
Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O., … & Zettlemoyer, L. (2019). Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461.
-
Sun, Y., Dong, L., Zhu, Y., Huang, S., Wang, W., Ma, S., … & Wei, F. (2024). You Only Cache Once: Decoder-Decoder Architectures for Language Models. arXiv preprint arXiv:2405.05254.
-
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., … & Sutskever, I. (2021, July). Learning transferable visual models from natural language supervision. In International conference on machine learning (pp. 8748-8763). PMLR.
-
Ziegler, D. M., Stiennon, N., Wu, J., Brown, T. B., Radford, A., Amodei, D., … & Irving, G. (2019). Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593.
-
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., … & Lowe, R. (2022). Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35, 27730-27744.
-
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347.
-
Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., & Finn, C. (2024). Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36.
-
Wu, Y., Sun, Z., Yuan, H., Ji, K., Yang, Y., & Gu, Q. (2024). Self-Play Preference Optimization for Language Model Alignment. arXiv preprint arXiv:2405.00675.
-
Hu, Z., Wang, L., Lan, Y., Xu, W., Lim, E. P., Bing, L., … & Lee, R. K. W. (2023). Llm-adapters: An adapter family for parameter-efficient fine-tuning of large language models. arXiv preprint arXiv:2304.01933
-
Zaken, E. B., Ravfogel, S., & Goldberg, Y. (2021). Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. arXiv preprint arXiv:2106.10199.
-
Liu, Z., Oguz, B., Zhao, C., Chang, E., Stock, P., Mehdad, Y., … & Chandra, V. (2023). Llm-qat: Data-free quantization aware training for large language models. arXiv preprint arXiv:2305.17888.
-
Dai, D., Sun, Y., Dong, L., Hao, Y., Ma, S., Sui, Z., & Wei, F. (2022). Why can gpt learn in-context? language models implicitly perform gradient descent as meta-optimizers. arXiv preprint arXiv:2212.10559.
-
Gloeckle, F., Idrissi, B. Y., Rozière, B., Lopez-Paz, D., & Synnaeve, G. (2024). Better & faster large language models via multi-token prediction. arXiv preprint arXiv:2404.19737.
-
LoRA is sometimes treated as a special case of an adapter module. In this post, I separated them as two different approaches given the popularity of LoRA. ↩︎